|
|
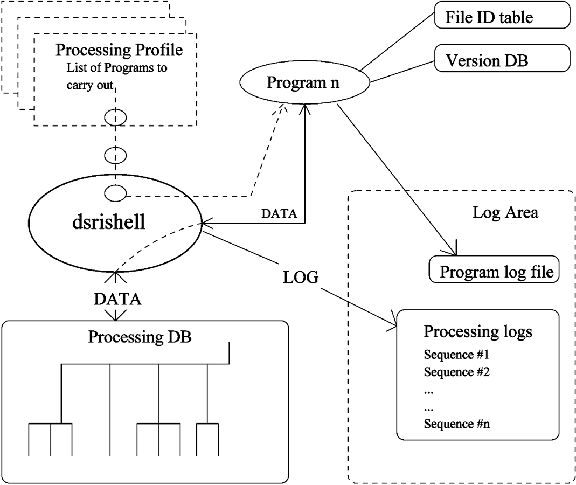
No strong centralized computing approach has been attempted for this project, but forums exist for discussion of common approaches, notably the Technical Implementation Committee (TIC) group. In general, institutes process their own data, and make available to IKI programs for processing the IKI share of data from their instruments. The Center for Astrophysics at Cambridge, Massachusetts will setup an overall archive for the data from the satellite they get rights to. Our software project is to some extent a 'discount' project - at least compared to other software projects such as the XMM and AXAF. This is not necessarily a weakness, but it has had profound influence on our approach to building the processing system. Keywords have been (and are) simplistic in design, using other people's ideas and methods, using existing software to the extent possible and maintaining modest ambitions. We have had only limited success in trying to involve outside resources in programming, due to limited project management resources. 2.1.2 Main Goals The main-goals of our software system are:For it to be 'suitable for scientific analysis' we intend the output data to be in a form where instrument signatures have been removed, and in a format that may be read by existing analysis software (ftools, IRAF/PROS, XANADU). We may get up to 320 MB of raw data per day (that's the theoretical maximum, defined by the size of the on-board disks of the 4 detectors). This amount is expected to multiply by at least a factor of p through the system, so a maximum load of 1 GB per day is realistic. We aim for a minimal load on personnel resources for the daily processing of data (2 operators). 2.1.3 Hardware Platform We have two types of computers in our processing configuration. One type is the PC, used as EGSE machines (Electronic Ground System Equipment), the others are SUN servers, used for the pipeline processing, archiving etc. of data. We anticipate to acquire one large multi-processor SUN server for handling the daily processing load. We also will acquire a smaller SUN server for the quick look analysis, plus a number of SUN servers for daily analysis at our premises by scientists, both those employed here and those visiting. Data will be written to CD's and to some extent to 8 mm tapes. CD's have been chosen due to the widespread use of CD drives.2.1.4 Software Given the main hardware platform, the obvious operating system to choose is Solaris 2, though we will consider updating this if and when SUN announces their next operating system update (which is likely to be some kind of Java-based system). Other software issues can be summarized as follows: (i) C and FORTRAN have been chosen as programming languages. We considered going directly to C++, but felt that we lacked sufficiently broad expertise, and preferred to stick to the better known languages. (ii) We use perl and normal bourne shell for scripts. (iii) We generally do not make GUIs (graphical user-interfaces) though for some applications this may be applied at a later time in the project. (iv) We will offer HTML-interfaces for observation-requesting, though. 2.1.5 FormatsAll (or nearly all) formats used by the processing system are based on the FITS standard. This choice was made because of the self-documenting nature of FITS. With the Binary Extension option, FITS has also become useful for almost any kind of data. We have followed the development in the High Energy FITS community closely, and intend to implement indexing schemes and other significant improvements to the standards as they emerge. Beside the qualities of the format itself, software for handling FITS data is available in the community - notably in the fitsio-package from HEASARC, which we use when dealing with FITS files. On a higher level, we have used a format very close to the RDF (Rationalized Data Format) format used by the ROSAT mission for event data. We have two RDF files; the Basic RDF file holding event data, GTI information, and other information with direct relevance to the event data. The other one is the ancillary RDF file holding attitude data, clock-correlation data, detailed hk data and other data, which have been used in constructing the event data. We overall refer to this format as DSRI RDF format, and hope no misunderstandings will emerge from this! For calibration data we use the HEASARC defined formats, where applicable. We also use a local version of the CALDB for archiving calibration data. Formats for time-lines, aspect-solution, orbit-solution and so on, have been defined in a Binary FITS format, by IKI. For database tables, used for instance for archiving and log purposes, we have adopted the RDB format (described in UNIX Relational Database Management from Prentice Hall, 1988, by Rod Mains et al.), see below for discussion of RDB. 2.2 Logical ModelThe logical model depicts the relationship between different data types and how they are processed to form new data types. Figure 1: The figure above shows somewhat schematically the logical model at a high level for the main bulk of the processing activities.2.2.1 Data types Data types are divided into logical types and format types: there may be many logical data types that all use the same type of format. As an example, uncorrected and corrected event files share the same format type, but belong to different logical types. Data are stored according to their logical data-type (plus some other parameters). 2.3 Processing ModelProcessing may be seen as the pipe-lining of different input-data to form different output-data. This processing has been made as automatic as we have dared to, thus minimizing operator load. The central tool for running the automated pipe-line is the DSRI-built tool called the drishell. Figure 2: The above figure shows on one side the dsrishell, executing the programs that are specified within a number of profiles and interacting with the file system based processing database. On the other hand, one program handles data as specified by the dsrishell, interacts with the file-id database and the version-database, and logs activity to the log area.2.3.1 The dsrishell The dsrishell controls the execution of the single program, on the basis of: 1: The purpose of the processing. 2: Unprocessed Available Data. One may define a number of pipelines, each with a given purpose (one could be to assemble all data pertaining to one observation into a basic RDF file). One such Pipeline consists of a number of Profiles, that again describe a sequence of Programs, so the levels are Pipeline - Profile - Program.
Below is a sample profile:
#---------------------------------------------------------------
# DSRI-software
# Subsystem: dsri-sys
# Directory: cmd
# Type: dsri
# Program-name: rff.prof
# Description: Profile for handling raw FITS fast data.
#--------------------------------------------------------------
# HISTORY:
#________________________________________________________
# 970603 ! morten! created.
#---------------------------------------------------------------
# SCCS-version string
#---------------------------------------------------------------
# sccsversion="@(#): rff.prof 1.1 06/20/97 DSRI"
#---------------------------------------------------------------
{
profile: rff.prof
mode: auto
num: $RFFNUM
}
# List variables.
# PROCSEQ is an built-in variable, set to the
# processing sequence number of this execution
# of the profile.
{
RFFNUM= 'pdb_filenum.pl -p rff2ev.x -s $PROCSEQ'
}
{
name: rff2ev.x
type: inputfile
command: rff2ev.x -i $INPUTFILE -s $PROCSEQ
}
{
name: pdb_delete.pl
type: file
command: pdb_delete.pl -i $INPUTFILE -s $PROCSEQ
}
{
name: sleep
type: file
command: sleep 10
}
This profile depicts two main elements of the system: the ability to define internal variables (here RFFNUM), that may be used to guide the processing (here decide how many available files exist, suited for analysis by the rff2ev.x program), and the listing of programs to run.The pipeline may be made to loop according to the amount of input data or infinitely. One may also create parallel running pipelines by branching (e.g. one branch handling HK data and another science data). Notice also that more than one dsrishell may be running at any time.The dsrishell logs execution to a processing log. Programs log errors and debugging messages to individual log files. Processing configuration and parameter files are also kept, as part of the processing log. All this is done on a per session basis. The dsrishell interacts with the processing database. It reserves available files for processing and releases them when processing is done. The processing database is based on the normal UNIX file system, using a directory structure that reflects the existing data types, and some parameters related to data.2.3.2 Database tools Besides the purely file system-based processing database, the other system databases rely on ASCII tables called RDB-tables. These are well-defined, and make use of the Starbase routines written at CFA (Center for Astrophysics) in Cambridge, Massachusetts for manipulating the files. This RDB choice was made because we found it to hard on our sparse manpower resources to acquire a professional database management system, given the particular expertise and maintenance that such a system requires. 2.4 Some particularsA number of particulars have been elaborated over a period of time. Among these are the following. 2.4.1 File-idEach file being handled by the system obtains a so-called file-id. This id is appended to the filename, and all files are entered in the file-id table including some information regarding the file (notably type of data that the file holds). The file-id table is an ASCII table in the RDB-format. 2.4.2 VersionsTo be able to trace the origins of a given file, both in terms of data sets used as input to generate the file, and programs used for the processing, we have set up a version database. This holds a version description for each file, from which the whole story of the file may be extracted.A sample version description looks like this: EVEG0.279.LEA- QM.a00000098:ft.00000.sod.0.8.a00000083:auto0052.fhl.a00000075:auto0052.fhl>srgrec.x@1.9@971016>r2rff.x @2.0@971016>rff2ev.x@1.3@971016 This rather cryptic looking line may - with the help of a small tool - be deciphered into the following: The file 'EVEG0.279.LEA-QM.a00000098' was created from inputfile(s) 'ft.00000.sod.0.8.a00000083' by the program 'rff2ev.x@1.3@971016' The file 'ft.00000.sod.0.8.a00000083' was created from inputfile(s) 'auto0052.fhl.a00000075' by the program 'r2rff.x@2.0@971016' The file 'auto0052.fhl.a00000075' was created from inputfile(s) 'auto0052.fhl' by the program 'srgrec.x@1.9@971016' The file auto0052.fhl has no versionWe may thus see which versions of what programs were used when generating the file, making it possible also to find out which files were generated with, e.g., a faulty program. In the above example, the usage of ID's is also clear, as is the indication as to when the processing was done. 2.4.3 Error-handling As indicated in the description of the dsrishell, all programs log errors to different outputs. For a normal program, the outputs are threefold: a particular program log, the processing-sequence log and a global error log. Logs are essentially divided into debug messages, warnings and fatal errors. Fatal errors are logged to all 3 logs. Errors are logged to the program log and the processing sequence log; the debugging messages to the program log only. The program log exists on a per processing sequence basis. 2.5 Requests for ObservationJuly 16th of 1997, the first AO for the so-called Danish core program took place. We used it for testing the software that receives and handles Observation Requests. This software has been developed by CFA, in Cambridge, Massachusetts. We have had to do some enhancements. The system has three main parts: a HTML interface, which may be used for filling out all necessary information for applying for observation time; a mail part, by which mails generated by using the HTML interface are deciphered; and an RDB based database part, where data pertaining to the Observation request are stored in different relevant tables. The main identifier is the Observation Request ID, which will stick to the observation and it's included sub-observations throughout the process - till data is received. 3. ConclusionsThe relatively few resources allocated for the implementation of our data processing has influenced the definitions of the goals set up for our processing system. The main goals will be to get a running, thoroughly tested, minimal system for launch; to enhance that system with further science analysis as part of the standard analysis, plus implementation of GUI's where applicable (and useful); to access archive data; to configure profiles for the pipeline etc., as resources become available. Without a well-working international community of High Energy Astrophysics Data centers, a good deal of standards and standard software and a general willingness in this community to be helpful, things would have been very difficult.  Proceed to the next article
Proceed to the next article
 Return to the previous article
Return to the previous article
HEASARC Home | Observatories | Archive | Calibration | Software | Tools | Students/Teachers/Public Last modified: Monday, 19-Jun-2006 11:40:52 EDT |

 Select another article
Select another article{kind=link}
{kind=link}