|
|
COSSC
Abstract
The need to archive vast amounts of data has become a major part of most scientific space missions. Grasp, the Generic Retrieval/Archive Services Protocol, addresses the question of how to provide a consistent interface for archiving the data collected in an environment where the underlying hardware archives and computer hosts may be rapidly changing. GraspFS and GraspDB, two working implementations of the protocol, demonstrate different approaches to implementing Grasp on a file system.
1. Introduction
Grasp, the Generic Retrieval/Archive Services Protocol, addresses the problem of creating a consistent front-end of simple archive services when the archive device and the host computer are changing regularly. Grasp insulates the archive user from the details of the archiving devices being used.
To the Grasp user, an archive is a black box into which files are written and from which files are retrieved. If a user wishes to store a file, or set of files, then the user provides the name(s) of the file(s) and a tag for Grasp to associate with the file(s). Grasp then stores the file(s) in the black box of the archive. Where the files are stored depends upon how the particular implementation is set up, but is normally of no concern to the user. The files are stored strictly on a space available basis.
Once Grasp copies files into an archive, the files are available to the user through the tag name that was supplied when archiving. To retrieve a file, or set of files, the user supplies the tag and a destination for the file(s). Grasp then copies the file(s) out of the archive into the destination area supplied. The original filenames of the files are maintained.
Files stored in a Grasp archive may be grouped. The reference tags can point to three different structures, either a single file, a set of any number of files, or to a virtual set of files. In Grasp, sets of files are called filesets and virtual sets of files are called derived filesets. Derived filesets consist of a list of pointers to other tags and/or files already in the target archive. A derived fileset is a useful tool for putting data common to many other groups of data, such as calibration files, together with those other files without having to waste space by storing the common file multiple times.
In order to maintain machine independence, files in a Grasp archive are stored in two parts. These two parts are the context and the data. For example, consider files on a VMS machine. Each file is designated as being of a certain type, record size, segmentation, etcetera, each of which may have some control information buried in the file system. When the VMS file is stored in a Grasp archive, the control information is stripped out of the file and stored in the Grasp archive as the context part of the file. The remainder of the file after the control information has been stripped out is a stream of data bytes which Grasp stores as the data part of the file.
Now, why bother separating the parts of the file if they're just going to be put back together? Well, if the VMS file is retrieved onto a Unix system, which only stores files as a stream of bytes, then only the data part of the VMS file, which is a stream of bytes, will be returned. If the VMS file is requested on a VMS system, then the data part of the file will be returned, and then the file will be restored to its original format using the context data stored in the Grasp archive. Each of the processes is invisible to the user of the archive.
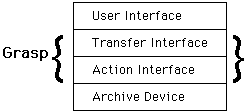
The Grasp protocol design has two distinct layers. The archive/implementation independent top layer provides a consistent interface to the user. The bottom layer changes to accommodate different implementations and/or archive devices.
The Grasp top layer, called the transfer interface, allows users to read, write, and delete data and to get the status of the archive and data. Grasp functions are available at both the command line and as subroutines. Grasp user functions all work with only three pieces of information, an archive name, file names, and tagnames which are ASCII strings used by Grasp to point to the files stored within an archive. The transfer layer of the Grasp interface is designed so that the code of a single implementation may be transported to many platforms.
The implementation of the Action Interface, the bottom layer of Grasp code, will change for each device/operating system to which the Grasp interface is ported. The Action Interface provides the atomic functions which are called by the Transfer Interface. The Grasp protocol defines a set of suggested atomic functions which provide the capabilities required to implement the Action Interface.
Two implementations of the Grasp protocol have been developed at the COSSC. Both of the implementations are based on an archive device which looks like a standard file system. GraspFS implicitly stores all information about the archive in the directory structures in which the archive is stored. For small archives, GraspFS is an ideal implementation with little overhead for storing data about the archive and complete independence from commercial software. GraspFS has been tested on DECstations, SparcStations, and VAXstations.
GraspDB is a more complex implementation of the Grasp protocol which uses a database to store information about the files maintained in an archive. Current multidisk spanning and future plans for multi-computer spanning archives make GraspDB an implementation of the Grasp protocol which is excellent for large archives. Although GraspDB is tied to using a database, all accesses to the database are made through the STDB function library which allows any of a number of databases to be used, including Ingres and Sybase. GraspDB is currently implemented on a DECstation, but much of the code derives from GraspFS, so that ports should not be difficult.
With the implementation of GraspDB, our experience with using GraspFS at the COSSC indicated that a set of archive management functions should be written to add to the capabilities of the Grasp protocol. A set of functions were designed and implemented which currently help with listing information about the archive.
At the COSSC, an archive which is expected to grow into hundreds of gigabytes is operational. The Compton Observatory archive initially operated with a user interface built over the GraspFS implementation of Grasp. When the archive grew beyond the scope of a single hard disk, it became necessary to add multidisk spanning to allow the archive to continue to grow. The GraspDB implementation replaced GraspFS in the archive. The user interface required minimal changes, none of which were related to the Grasp protocol. Currently, the COSSC archive is spread over four hard disks and is still growing. Plans are underway to transfer the archive to an optical jukebox which looks like a Unix file system. The transfer will require no changes in the GraspDB implementation.
2. Design Concept
Grasp is a non-hierarchical archiving protocol. Each Grasp archive consists of a set of tags which point to data stored in the archive. Tags in a Grasp archive refer to a certain amount of data in the archive which may take three forms.
In the first type, a Grasp tag may point to a single file in an archive. Second, a Grasp tag may point to multiple files in an archive, the collection of files formed is referred to as a fileset. When a tag of this second type is read from the archive, then all of the files associated with the tag are copied from the archive to the destination given. In table 1 then, if a user requests tag2a from a Grasp archive, then the files x.dat, y.dat, and z.dat will be copied to the user supplied destination.
The third type of data storage in the Grasp is the most complex. In it, a tag points to a set of tags and/or files which are already stored in the archive. This type of data collection is called a derived fileset. In table 1, tag3 is an example of the data that a derived fileset might point to. In the example, tag3 contains tag1, a pointer to a single file, tag2b, a pointer to a fileset containing multiple files, and, the files x.dat and y.dat from tag2a. If a user requests that the data associated with tag3 be copied out of the Grasp archive, then the files a.dat, b.dat, m.dat, x.dat, and y.dat will be copied to the user supplied destination with their original filenames.
Grasp is a two layer system. The Transfer Interface is computer/archive device independent code while the Action interface contains code which is dedicated to each computer/archive device addressed. The Transfer Interface is simple, with only a few calls. The Action Interface is more complex.
A typical system using Grasp for archiving would have a structure resembling the following outline:
2.1 The Transfer Interface
The Transfer Interface is based on a set of atomic functions implemented in the Action Interface. Functions at the Transfer Interface level interpret user commands and translate them into a possibly complex series of actions in the archive, e.g., when the a user requests that Grasp archive a list of files, the implementation must first check that there is enough space, then archive each file. The functions implemented at the Transfer Interface level are described in section 3.
At the Transfer Interface layer, Grasp is modeless, i.e., the actions of calls are independent of one another (except possibly for running out of space in the archive). Users can call functions in any desired order, possibly with calls affecting a number of different archives. Whenever control is returned to the user from the Transfer Interface, Grasp guarantees that the archive is in a valid state.
Operations at the Transfer Interface level use only three items of information, file names, tag names, and archive names. Separation of the Transfer Interface from the operating system is easily maintained using these names. The archive and tag names are ASCII strings. Individual archives are addressed by an archive name assigned by the creator of the archive. Once a file or fileset has been archived, it is referenced only by a tag which has a tagname specified by the user. Only the file name is system dependent as it may contain a path name, but subfunctions within the Action Interface are used to parse these strings for operating system dependencies.
2.2 The Action Interface
At the Action Interface level, atomic functions are defined for the Grasp system which perform archiving procedures on single files. Additionally, functions are defined which return information on individual files in the archive.
Some examples of the functions implemented in the Action Interface are OpenArch and CloseArch, which open and close a Grasp archive. PutFile, GetFile, and DeleteFile are functions which store, read, and delete single files in a Grasp archive. Sets are managed with CreateSet and DeleteSet.
For maximum flexibility, the Action Interface works with files in two parts, the data and the context. The context of the file consists of the specification of the type of file. For example, under the VMS operating system, files may have many formats, from fixed length sequential to varying length random access. The context of the VMS file is this format information. The data of the VMS file is the stream of bytes left in the file after format information has been stripped out. At one extreme, Unix systems represent all files as streams of bytes, so there is no context information for standard Unix files.
The advantage of context and data separation are evident when files are archived from VMS to a UNIX archive. The context information stored in the archive can be used to restore the archived file to its proper VMS format. If this data is retrieved to a Unix system, then user software might need to be written to interpret some of the more sophisticated VMS formats, but in many cases the stream of bytes will be directly usable.
3. Transfer Interface Functions
Grasp comprises four areas of archive operation: reading, writing, deletion, and status information. Reading, writing, and deletion work on either a single file or a group of files.
A user can archive a group of files as a files either by explicitly specifying a list of files, or by using wild cards in the file specification. When a user specifies a tagname to be read or deleted Grasp knows whether a single file or multiple files are involved.
When deleting filesets, the results depend upon whether it is a regular or derived fileset. When a regular fileset or a single file is deleted, the actual files involved are deleted from the archive. If there are any derived filesets based on these, it is the user's responsbility to ensure that these are also deleted. When a derived fileset is deleted, only the pointers to the regular filesets are lost, i.e., the tagname used for the derived fileset becomes undefined.
Status commands in the Grasp system determine the state of the archive and the state of tags within the archive. The ability to store files and the remaining space in a file system can be queried, as may the association of a tag. If desired, a valid, unused tag name can be requested.
Grasp functions work both from the operating system command line and as function calls within a program. The Transfer Interface commands in Grasp are described in Appendix A using the command line form and function call form. The command line interface to Grasp is a simple layer which calls the function interface appropriately.
4. Grasp Implementations
Two implementations of Grasp are currently available at the COSSC, GraspDB and GraspFS. GraspFS is the original version of Grasp and stores archive information implicitly in the file structure of an archive. GraspDB is the newest version of Grasp and stores archive information explicitly in a database. Both implementations of the Grasp protocol store archive data in a set of directories on a generic device accessible as a file system.
4.1 GraspFS
GraspFS is currently implemented to handle archives which are stored in a single archive directory, and thus, on a single archive device. In this implementation, GraspFS is most useful for small archives with little space for overhead.
GraspFS has been implemented as a C program on Unix and VMS. The Transfer Interface is written in strict ANSI standard C so as to be as transportable as possible. The Transfer Interface currently runs, with no modifications, on DECstations, SPARCstations, and VAX/VMS systems.
The Action Interface runs on the same three systems. The SPARCstation and DECstation versions of the Action Interface are identical, while the VAX/VMS version has minor variations which are placed, using C precompiler statements, in the same code.
The GraspFS implementation uses the inherent file system structure of each operating system as the database for the archive. This approach greatly simplifies the program implementation from a data storage point of view, but must deal with the path naming schemes of individual operating systems. To address the complexity of working with the different path naming schemes, a number of small functions modularize the path interpretation/construction processes. This modularization was also designed to accommodate reprogramming the Action Interface for a variety of archive devices.
In GraspFS, archives are built as a directory tree. Each archive has its own directory. Single files are stored in the top level of the directory. Filesets are stored as subdirectories of the main archive directory. Derived filesets are implemented as a set of pointers which take up minimal space. In the Unix version, the pointers are implemented as soft links. The VMS version of GraspFS uses path names within files in the derived fileset to point to the actual file being referenced. Note that in GraspFS, the original names of single files stored in an archive are not currently preserved, but that will change in a later version.
As an example, lets look at how the tags listed in table 1 would look if they were stored in a GraspFS archive named Xdat.
/archloc/grasp/Xdat: <- Top level archive directory tag1 <- Single file tag2a: <- Directory x.dat <- Single file y.dat <- Single file z.dat <- Single file tag2b: <- Directory a.dat <- Single file b.dat <- Single file tag3: <- Directory tag1 <- Link to /archloc/grasp/Xdat/tag1 x.dat <- Link to /archloc/grasp/Xdat/tag2a/x.dat y.dat <- Link to /archloc/grasp/Xdat/tag2a/y.dat a.dat <- Link to /archloc/grasp/Xdat/tag2b/a.dat b.dat <- Link to /archloc/grasp/Xdat/tag2b/b.dat
Using this example, to determine whether a tag existed in the Xdat archive, Grasp gets a directory listing of the /archloc/grasp/Xdat directory. If the name of the tag of interest is in the listing, then the tag is in the Xdat archive. To read a tag from the archive, for instance tag2a, Grasp would copy all of the files from the /archloc/grasp/Xdat/tag2a directory to the user specified destination.
Context and data separation is not currently implemented for the VMS version of GraspFS, but the software to perform the separation exists and will be integrated into the Grasp system.
4.2 GraspDB
GraspDB has been implemented as a C program on a DECstation running Unix. The Transfer interface is essentially the same as that for GraspFS, but some changes have been made to improve the flow of the code and to detect errors better. The principle of adhering strictly to ANSI C was maintained in the Transfer interface.
The GraspDB Action Interface indirectly uses an Ingres database via STDB to store information about an archive. Explicitly storing information about the archive enhances the ability of Grasp to deal with the issue of identifying where a file is located in multidisk and future multicomputer archives.
The GraspDB archive database consists of four tables named, archives, users, tags, and files. The tables have the structure described in Table 2.
The archname and filename parameters are the key relationships in the database. Each record has an archname entry. The tagname parameter is used to link the tags and files tables. With GraspDB filesets are created with one record in the tags table and multiple records in the files table, all of which share the same tagname entry. The contextpath and datapath entries in the file table contain the full path to the file stored in the archive which is recorded by the files table record. Derived fileset storage is similar, but the contextpath and datapath entries are left blank. Instead, the sourcetag entry is filled with the name of the tag that the fileset is derived from. Note that the contextpath is not presented in the example below as the data/context separation feature is not implemented in the current (first) version of GraspDB.
The STDB function library, developed at STScI, was ported to Ingres at the COSSC. STDB is already available for Sybase and OMNIBase. STDB has two goals, to isolate the user from the intricacies of database preprocessor coding, and, to provide a uniform interface to a variety of databases, i.e., it provides much the same functionality for databases that Grasp provides for archives. To maintain an open system, Grasp uses only standard SQL statements going through STDB to access Ingres. Thus, rather than Ingres, any other database supporting standard SQL could be used by GraspDB with no modification to GraspDB code and only minor (if any) modification to the SQL statements.
Now, for comparison with GraspFS, lets look at how the tags listed in table 1 would look if they were stored in a GraspFS archive named Xdat, and what the database tables storing the information about the Xdat archive would look like. The directory structure for a small archive is very simple.
/archloc/grasp/Xdat: <- Top level archive directory m.dat-tag1 <- Single file x.dat-tag2a <- File that is part of fileset tag2a y.dat-tag2a <- File that is part of fileset tag2a z.dat-tag2a <- File that is part of fileset tag2a a.dat-tag2b <- File that is part of fileset tag2b b.dat-tag2b <- File that is part of fileset tag2bNote that the derived fileset associated with tag3 has no files in the archive because it is created strictly from pointers to other files already in the archive. In a GraspFS archive, these pointers are stored as links. In the GraspDB archive, the archive database stores the paths of the files in the derived fileset.
Table 3 shows the archive database for the tags in Table 1. Note that some of the columns in the table are left out for conciseness.
In the archive database, note that archname column is the common relation running through all the tables. The tagname column is the relation which binds the tags and files tables.
Explicitly storing archive information gives GraspDB the advantage of making it easier to track file locations. In GraspFS, file locations are determined by appending the name of the tagname of interest to the known location of the archive. Since a GraspFS archive only exists in one location, there is no problem of determining what path to use but this lack of flexibility makes it difficult to support data on multiple file systems. The major impetus for implementing GraspDB as the next generation of Grasp was multidisk spanning. Explicitly storing archive information in a database makes it easy to distribute files among a number of locations.
As each file is written into the GraspDB archive, the storage path for each part of the file, context and data, is determined individually. The storage path for each file in the archive is then stored in the contextpath and datapath entries of the files table GraspDB need only find the location for the file when it is archived. Later, a simple query will return the full path needed for accessing the file.
This approach leads naturally to a the capability to archive over multiple devices. The GraspDB file placement algorithm circulates through a list of paths associated with the archive at the time it was created. The device which each path points to is examined to determine whether it has sufficient space to store the current file of interest. If the device does not have sufficient space, then the next device is checked. The storage across multiple devices is completely transparent and creates the illusion that multiple devices are actually a single larger device.
The implementation of GraspNet is our next planned step beyond the current multidisk spanning GraspDB. GraspNet will allow Grasp to archive files not just on multiple disks, but also on multiple machines and archive device types. GraspNet works in conjunction with GraspDB. GraspDB works as it normally does, but, it also has available a number of paths which point to other machines. When GraspDB encounters an nonlocal address, it notifies GraspNet with the address and the information which was requested.
Other features of the GraspDB implementation are directory binning and automatic expansion. Binning addresses a problem with GraspDB regarding the number of files in a directory. GraspFS disperses the files in an archive into subdirectories through the fileset structure. Without binning, GraspDB would put all of the files in an archive into a single directory until there is no more space on a device. The problem with this is that if a very large number of files are all placed in the same directory then searches for files in that directory may be inefficient. It can be faster if files are broken into a tree of subdirectories. GraspDB uses binning to solve this problem. Files in an archive may be binned into a number of different subdirectories with a limit on the number of files allowed in each bin (subdirectory). The bin subdirectories are invisible to users of Grasp and only affect the response of the system.
GraspDB's automatic expansion feature takes over when all of the devices pointed to by paths stored in an archive's archpaths record are filled. At that point, if automatic expansion is turned on, then GraspDB will check the ARCHIVE_LOC environment variable to find out if it has any paths not already in an archive's archpaths. If any new paths are found, then the devices they point to will be checked for storage space. When a device is found that meets a settable emptiness criteria, which defaults to about 25% of a devices space free, then GraspDB adds that new path to archpaths and starts storing archive data at the new archive location.
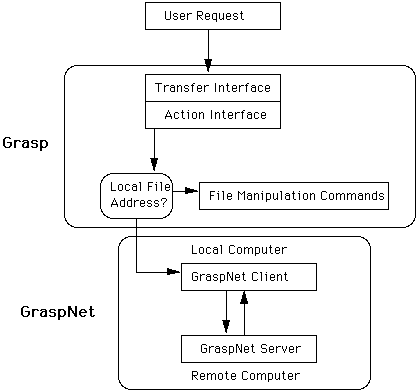
5. Archive Management Functions
From our experience with maintaining the original GraspFS style archive for the COSSC, it was apparent that manager functions would be a useful addition to the Grasp function suite. These functions are not primarily intended for casual users of the archive, but for the personnel who maintain the system. Only privileged personnel will normally use most of these functions.
The GraspManager function suite consists of nine functions used to create, manipulate, and delete archives. The functions are divided into three categories, archive manipulation, user manipulation, and informational. These functions are described in Appendix B.
6. Future Directions
As discussed above, the next step for Grasp will be the development of GraspNet. The implementation of GraspNet should also support the use of context information to allow us to store VMS files of arbitrary type within Grasp. We also wish to increase the portability of Grasp. Increasing the portability of GraspDB will require divorcing GraspDB from Ingres and installing a non-proprietary database system. Our current best guess is to use a generic SQL server which can manage the simple Grasp databases efficiently. Any ideas or suggestions from readers would be welcome. The database should be accessible through STDB calls (possibly after a port of STDB).
7. For More Information
More information can be obtained from Jim Jordan at:
jmj@enemy.gsfc.nasa.gov (Internet) grossc::jmj (SPAN)
The source code for the latest versions of the GraspFS and GraspDB implementations, the specification paper and this paper, may be obtained via anonymous ftp from enemy.gsfc.nasa.gov in the Grasp directory.
The GraspManager functions, which are only currently implemented for GraspDB, are in the GraspDB directory. The source code for the Ingres version of the STDB function library is also available from the same location.
Appendix A: Examples of the basic Grasp functions
GrWrite archive filename tagname
status = GrWrite(archive, filename, tagname)
This function writes a file filename to archive which is to be associated with a tag named tagname. If filename is preceded by a `@' it is the name of a file with a list of files to be archived in an explicit fileset. For example, referring back to table 1, tag1 would be written into the archive Xdat with the command:
GrWrite Xdat m.dat tag1
Into the same archive, tag2a from table 1 would be written with the command:
GrWrite Xdat @fslist tag2a
where the fslist file contains the following three lines:
x.dat y.dat z.dat
Note that tag3 in the table 1, the derived fileset, would not be created with GrWrite, but rather with GrMakeFileSet.
GrRead archive tagname destination
status = GrRead(archive, tagname, destination)
This function reads a tag tagname from archive and stores it in destination. If tagname refers to a fileset, then destination is considered to be a location, typically a directory, to put the fileset files. If destination refers to a directory and tagname points to a single file, then that file will be copied to destination.
Referring again to table 1 and the Xdat example archive, reading tag1 from the Xdat archive would require the following command:
GrRead Xdat tag1 /home/fred/data
The GrRead command would copy the file m.dat, which is the only file associated with tag1, to the directory /home/fred/data.
To read tag2a from the Xdat archive to the same destination as the previous example, the following command would be used:
GrRead Xdat tag2a /home/fred/data
In this case, the three files associated with the tag tag2a, x.dat, y.dat, and z.dat, would all be copied to the /home/fred/data directory.
GrDelete archive tagname
status = GrDelete(archive, tagname)
GrDelete deletes tagname from archive and handles deletion of single files, regular filesets, and derived filesets. Note that the deletion of a derived fileset removes no actual files, just the record of the derived fileset.
Continuing with the same examples as before, to delete tag1, a user would issue the command:
GrDelete Xdat tag1
The fileset associated with tag2a would be deleted similarly with:
GrDelete Xdat tag2a
In both of thee examples, the files associated with the tag are also deleted. For the derived fileset from table 1, tag3, the same type of command
GrDelete Xdat tag3
deletes the reference to the derived fileset, but, the file of the fileset are not deleted.
GrMakeFileSet archive filesetlist tagname
status = GrMakeFileSet(archive, filesetlist, tagname)
Derived filesets are created with this function. Here, filesetlist refers to the file which contains the list of tagnames to be included in the derived fileset.
GrMakeFileSet is the command used to create derived filesets such as the one pictured as tag3 in table 1. To create the derived fileset associated with tag3, assuming that tag1, tag2a, and tag2b are already archived, the following command would be issued:
GrMakeFileSet Xdat dfslist tag3
The name dfslist is the name of the file that the tags which will make up the derived fileset are listed in. The file dfslist would have the following contents to create tag3:
tag1 x.dat@tag2a y.dat@tag2a tag2b
Note that in the command, the name dfslist was not preceded by an `@' as the name fslist was in GrWrite. This is because a file name must always be supplied in GrMakeFileSet.
GrCanStore archive filename
status = GrCanStore(archive, filename)
GrCanStore queries archive to see if it has enough space to store the file(s) specified by filename.
The filename parameter in the GrCanStore command has the same syntax as the filename parameter in the GrWrite command. Thus, to determine whether a single file can be stored in an archive, issue the command:
GrCanStore Xdat m.dat
To determine whether a list of files can be stored, using the @fslist file example as in GrWrite, use the command:
GrCanStore Xdat @fslist
GrSpace archive
size = GrSpace(archive)
The amount of space (in kilobytes) available in the archive is returned by this function. The command
GrSpace Xdat
will return the number of kbytes of storage space which is available in all of the areas available to Xdat for archiving.
GrStat archive
status = GrStat(archive)
This function checks whether archive is available. If used on the command line with no arguments, it lists the available archives.
GrTag archive
status = GrTag(archive, tagname)
A valid, unused tagname is returned by this function if possible. The format of the tag is unspecified, but in the COSSC implementations of Grasp, a tagname is returned with the format archive-number. For instance, tha call:
GrTag Xdat
might return Xdat-23 as a unique tagname.
GrTagStat archive tagname
status = GrTagStat(archive, tagname)
The association of tagname with a single file or fileset is checked and returned by this function, i.e., the value of status indicates whether or not a tagname has been used and if so if it is used for a single file, a fileset or a derived fileset.
GrPrStat status
message = GrPrStat(status)
This function returns a string explaining the meaning of the numeric status codes returned by the other Grasp functions. All of the status returns are integers which may be plugged into GrPrStat to find the string description of the status return.
Appendix B: Examples of the GraspMan archive management functions
The archive manipulation functions are GrMcreate, GrMdestroy, and GrMmodify.
status = GrMcreate(archname,archpaths,archtype,nexttag)
GrMcreate creates the new archive archname by putting the appropriate entries into archives table. Optionally, archpaths, archtype, and nexttag may be specified. All of the optional values have defaults, with archpaths relying on the presence of an ARCHIVE_LOC environment variable.
status = GrMdestroy(archname,totalflag)
GrMdestroy destroys the old archive archname by removing the database entries for the archive from all of the GraspDB tables. If totalflag has a value of 1 then the files in the archive are also deleted from the system. Only a value of 1 will cause the files to be deleted.
status = GrMmodify(archname,archpaths,archtype,nexttag)
GrMmodify is used to modify the archpaths, archtype, and nexttag entries associated with the archive archname.
The GraspManager user functions are GrMaddUser, GrMremoveUser, and GrMuser.
status = GrMaddUser(username,archname,authstr)
GrMaddUser adds read or authstr privileges for username to the GraspDB archive database. If archname is not specified, then the privileges will be extended to all current databases. As the archive becomes more distributed the need to define which users have the rights to delete and modify the archive becomes more critical.
status = GrMremoveUser(username,archname)
GrMremoveUser eliminates username from the users table in the archive database. If archname is specified, then only the username entry associated with that archive is deleted.
status = GrMuser(username,archname,authstr)
GrMuser is used to modify the authstr privileges of username for the archive archname.
The GraspManager functions used to list information about a GraspDB archive are GrMlist, GrMlistLocs, and GrMsize.
status = GrMlist(selection,archname)
GrMlist will print out a list of information about selection from all archives, or only from archname if specified. The selection may be any of a (archives), u (users), t (tags), or f (files).
status = GrMlistLocs(archname,tagname)
GrMlistLocs is used to print out the directory locations of all the files pointed to by tags in the archive archname. Note that if multi-disk spanning and/or binning are being used, then a fileset may have multiple locations. If tagname is specified, then only the locations for the tag specified will be listed.
size = GrMsize(archname)
GrMsize returns the size of the named archive in kilobytes.
The original use of a GraspFS style archive at COSSC also provoked the writing of another function, fs2db, which transfers a GraspFS style archive into a GraspDB archive. The command:
fs2db source_archive_path destination_archive_name
will write all of the files from the source archive into a destination archive which it creates. The structure of all filesets is maintained as is that of derived filesets.
 Proceed to the next article
Proceed to the next article
 Return to the previous article
Return to the previous article
HEASARC Home | Observatories | Archive | Calibration | Software | Tools | Students/Teachers/Public Last modified: Monday, 19-Jun-2006 11:40:52 EDT |

 Select another article
Select another article