|
|
NOTICE:
This Legacy journal article was published in Volume 1, May 1992, and has not been
updated since publication. Please use the search facility above to find regularly-updated
information about this topic elsewhere on the HEASARC site.
|
Astro-D: Plans for the Data Processing System
Charles Day1, Keith Arnaud1,
and N. E. White2
1: Astro-D GOF, 2: HEASARC
Introduction
Astro-D is Japan's fourth cosmic X-ray astronomy mission and the second
for which the US is providing a significant part of the scientific payload.
Scheduled to fly in February 1993, its four large-area telescopes will focus
X-rays from a wide energy range onto a pair of CCDs and a pair of imaging Gas
Scintillation Proportional Counters (GSPC). Astro-D will be the first X-ray
imaging mission operating over the 0.5-12 keV band with high energy resolution
(8 and 2 percent at 5.9 keV for the GSPCs and CCDs, respectively). The spatial
resolution of the mirrors, i.e., the half-power diameter of the point spread
function, will be 2.9 arcmin. This combination of capabilities will enable a
varied and exciting program of research to be carried out by US and Japanese
astronomers.
Although the designed lifetime is one year, the mission is expected to last
about five years, to generate 200 Mbytes of raw data per day, and may observe
up to seven sources per day. The eventual mission archive will contain up to
300 Gbytes of raw data. Since the Astro-D Guest Observer Facility (GOF) and
the HEASARC both come under the Office of Guest Investigator Programs (OGIP),
the data processing system can be designed to populate the Astro-D archive
automatically and in accordance with HEASARC standards. Another advantage of
the close association of the HEASARC, Astro-D GOF, as well as the ROSAT GOF, is
that software is being written in a multi-mission way as far as possible.
This article describes, in general terms, the plans of the Astro-D GOF to
provide an efficient, user-friendly data-processing system.
Data and Data Processing
Overview
The key elements of the design philosophy of the data processing system
are:
the conversion of the raw data from the mission- specific formats to a
HEASARC standard FITS format as soon as possible;
a pipeline of simple, modular design which can be run interactively by GOs and automatically by the GOF;
the smooth and automatic archiving of data and data products;
the separation of mission-dependent and generic modules.
The data processing system is being designed and built in close collaboration
with Japanese astronomers at ISAS, with the aim of ensuring that the same
processing software will run in the US and Japan. Furthermore, existing
software, such as the IRAF/PROS and XANADU analysis packages, will be used as
much as possible. Software is being written with a multi-mission flavor so
that it can be used for other missions. This is a feasible design goal, since
data from BBXRT, HEAO-1 A2, HEAO-2 SSS etc., will be reformatted to formats
closely resembling those used for Astro-D.
The processing pipeline is shown symbolically in Figures 1-3. Three stages are
identified:
ingestion and reformatting,
concatenation, selection and filtering,
analysis.
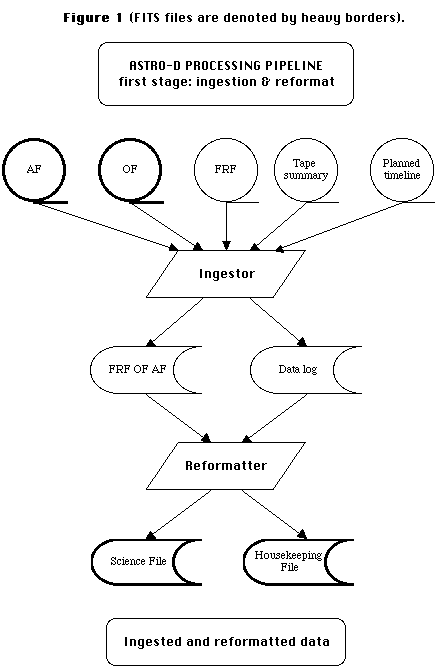
Stage-1 processing: ingestion and reformatting
The first stage of processing is shown in Figure 1. The data from
Japan, comprising the telemetry data (First Reduction File, FRF), the Orbit
File (OF), the Attitude File (AF), as well as the planned timeline and an
observation summary, are ingested by the database management system. After
ingestion, the format of the data is changed from the Astro-D specific format
to the self-defining FITS format with no loss of information. By reformatting
early in the pipeline, we ensure that all the raw data are available to users
in a standard format. At this stage, during the reformatting, the scientific and
housekeeping data are separated. For each instrument (two SIS, two GIS) and for each change
of mode, a Science File (SF) and Housekeeping File (HKF) are produced. The SF
will be similar in format to the revised ROSAT FITS files and will contain the
attitude and orbit information in the AF and OF.
Figure 1
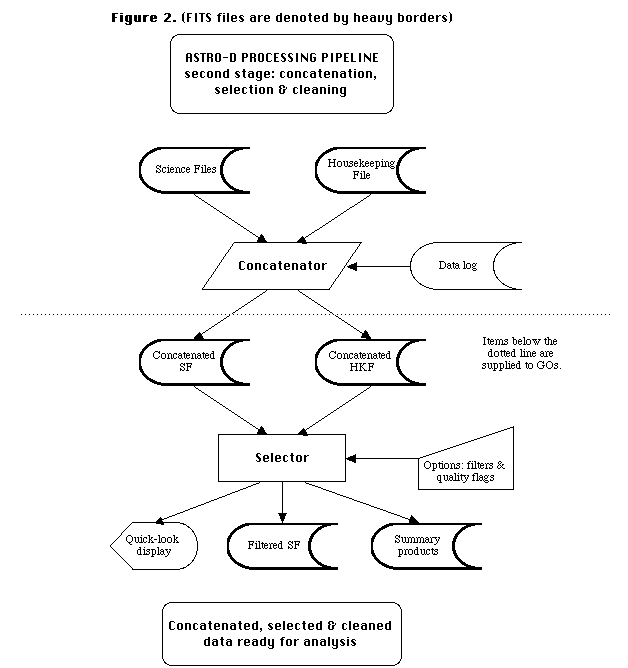
Stage-2: Concatenation, Selection and Filtering
The second stage of processing is shown in Fig.2. After reformatting, a
simple program, the Concatenator, groups together SF and HKF associated with
same observation. An observation is defined as the data from a single pointing
for a single PI.
The next important step is the selection and filtering of the data to be
analyzed. This is to be done by a program called the Selector which is
intended to be the central hub around which data selection and analysis takes
place. It will allow the user to select observations, apply filters, check the
status and details of these filters, examine the results of such selections,
and create a filtered SF as the output. The multi-task nature of the Selector
is best realized as a series of free- standing, clearly defined tools, chained
in macros if necessary, and mediated by a single user interface program. In
order to concentrate first on the selection algorithms, the prototype Selector
will be built within the IRAF environment, taking advantage of the flexible
parameter-passing mechanism of IRAF. A XANADU-like user interface will be
developed in parallel. For both the IRAF and XANADU versions, a command-driven
interface will be developed first, the structure of which will be optimized for
the subsequent overlaying of a Graphical User Interface (GUI).
Clearly, the functions performed by the Selector are required by almost any
orbiting X-ray or gamma-ray observatory, so, from the outset, the Selector is
being designed to be a multi-mission program. From the user point of view, the
Selector inputs and outputs are as follows.
Inputs:
concatenated SF and HKF
calibration data files
user-applied filters, quality flags, either as keyboard
input or as files
macros, script files (for batch or pipeline applications)
Outputs:
filtered SF and HKF in formats that IRAF/PROS and XANADU can read
summary products, such as images, spectra, light
curves, HK and attitude histories
access to quick-look display for plotting the summary products
log files containing the functions applied in the same
format as the script
files
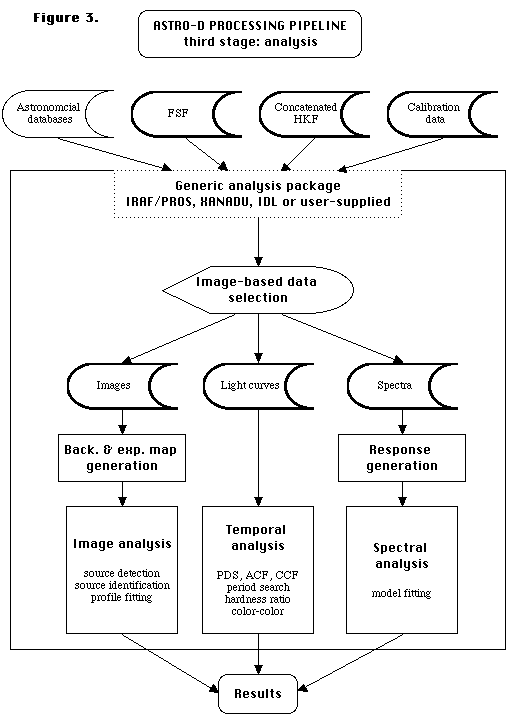
Stage-3: Analysis
the analysis stage of the processing is shown in Figure 3. The
principal output from the Selector is the Filtered Science File (FSF)
containing the subset of data which the Guest Observer (GO) wishes to analyze. Modifications to XANADU and to IRAF/PROS will enable these programs to read in
the FSF and HKF (the SF too, since the FSF and SF differ quantitatively not
qualitatively). After displaying the image, with SAOIMAGE (IRAF/PROS) or with XIMAGE (XANADU), the GO will then select part or parts of the image for
scientific analysis. The production of light curves for further temporal
analysis is the most straightforward: once a region of the field of view,
e.g., an X-ray binary, and its immediate vicinity, has been selected, a light
curve file can be generated for display and for further analysis by a program
such as XRONOS (XANADU). Spectral analysis, on the other hand, is more complex
because a response matrix is required. Due to variations across the field of
view of the detectors (the GIS and SIS), the response matrix has to be generated each time a spectrum is
integrated from the region of interest. This will be done by a free-standing
program which will read the header of the spectral file and consult the
appropriate calibration files and HKF. The same idea lies behind the
generation of background and exposure maps for image analysis: a free-standing
program will read the header of the FSF, and consult the appropriate
calibration files and HKF to generate the maps.
Figure 2
Automatic, "pipeline" processing
As mentioned above, the processing software will be designed to be run
interactively by GOs and in batch by the Astro-D GOF. The products of
automatic analysis will be directed to the Astro-D archive which will also
include catalogs and the data themselves. Access to data and data products in
the archive will be subject to a year-long moratorium in the case of US data.
Japanese and US/Japan data will be made available after a longer, as yet
undetermined, period.
Figure 3
 Proceed to the next article
Proceed to the next article
 Return to the previous article
Return to the previous article
 Select another article
Select another article
HEASARC Home |
Observatories |
Archive |
Calibration |
Software |
Tools |
Students/Teachers/Public
Last modified: Monday, 19-Jun-2006 11:40:52 EDT
|

{kind=link}
{kind=link}
{kind=link}